
例えば、テキストファイルに含まれるレコードの中から重複した行を削除するには、単純にuniqコマンドを実行するだけで解決するのですが、特定の文字が重複した行を抽出するには、オプションを付けてsortコマンドとも併用します。
uniqコマンドの基本
uniqコマンドは、単純に全く同じレコードが連続した場合に、重複した行を削除して出力してくれます。
例えば、以下のようなデータを含むファイルがあった場合、
111
222
222
333uniqコマンドを実行すると、
uniq [ファイル名]出力結果はこのようになります。
111
222
333uniqコマンドのオプション一覧
uniqコマンドはオプションを付けることによって、出力形式や比較対象を指定することができます。
| オプション(省略) | 意味 |
|---|---|
| -c | 各行の前に出現回数を出力する |
| -u | 重複していない行だけを出力する |
| -d | 重複した行だけを出力する |
| -D | 重複する行を全て出力する |
| -i | 比較時に大文字と小文字の違いを無視する |
| -w N | 行の比較を最初のN文字で行う |
| -s N | 最初のN文字を比較しない |
| -f N | 最初のN個のフィールドを比較しない |
| -z | 最後にNULL文字を出力す |
オプション情報はググったらすぐに見つかりますよ!
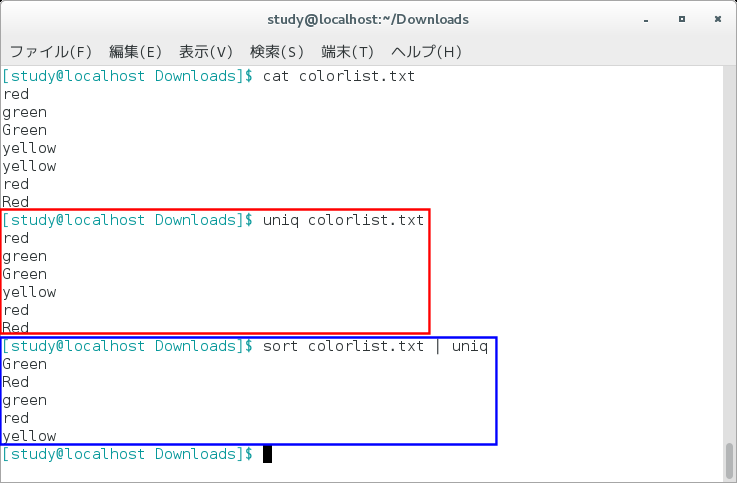
特定の文字を比較して重複行のみ抽出
冒頭でも記述した通り、uniqコマンドだけでは離れた行にある重複したデータを抽出できませんし、オプションを付けないと1行全てを完全一致で比較して、重複した行は削除されてしまいます。
そこで、レコードの並び替えを行うsortコマンドと、-w、-dオプションを利用して実現します。
sortからのuniq
例えば、内容が以下のようなファイルがあったとします。
111
222
333
222ここでは、222が重複しているのがわかりますが、連続したレコードではないため、単純なuniqコマンドでは重複を抽出できません。
そこで、sortコマンドの後にパイプ(|)でuniqコマンドを繋げて実装します。
sort test.txt | uniqすると、結果は前述と同じになります。
比較する文字数を指定する-wオプション
例題です。
111 aaa
222 bbb
333 ccc
222 ddd一見、後ろのアルファベットが全て異なるので、重複しているデータはないのですが、先頭の3文字が一致するデータがありますね。
この先頭の3文字のみで比較する場合に、-wオプションを利用します。
sort test.txt | uniq -w 2このように実行すると、結果はこうなります。
111 aaa
222 bbb
333 cccちなみに、-wの後ろの数字が文字数なのですが、最初の1文字目は0で指定します。
コンピュータのお決まりですね。
0が1、1が2、2が3・・・と言った感じです。
重複したデータのみ抽出する-dオプション
先程と同じデータを使って、-dオプションを追加してみると、
sort test.txt | uniq -d -w 2結果はこのようになります。
222 dddこれで、やりたかったことが完成しました!
余談ですが、行の先頭から何文字ではなく、途中から比較する場合には指定した文字数分スキップする-sオプションが使えますし、もしスペースやタブ区切りのデータだった場合、比較しないフィールドを指定できる-fオプションも重宝すると思います。
コメント